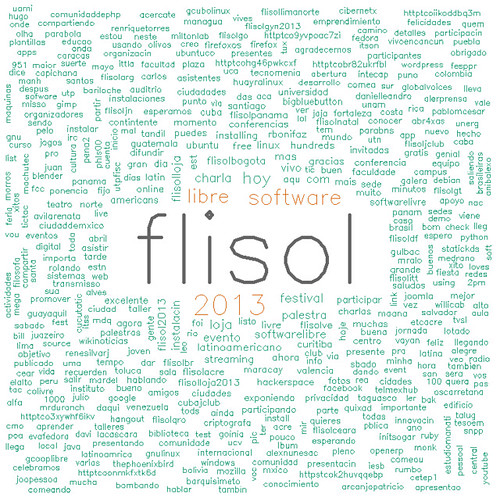
Una nube de palabras sobre el flisol 2013. durante el transcurso del flisol estuve obteniendo los tweets que al menos algunas de estas 3 palabras hiciera mención: flisol flisolve flisol2013 y bueno aproximadamente sólo 1800 tweets obtuve hasta las 6pm de Venezuela.
un sort al archivo, y colocando todo en un sólo archivo, arrojó las siguientes imagenes:
Usuarios (screen_name).
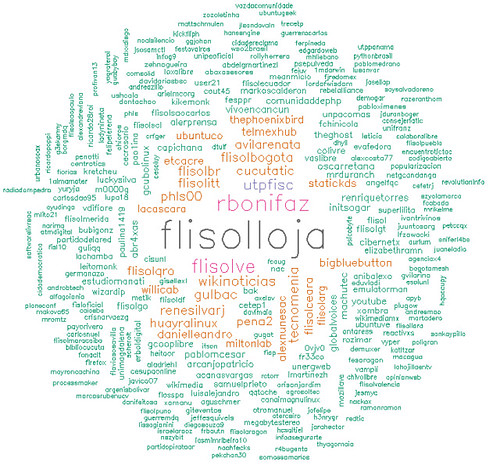
Tweets frecuencia > 10

Todos los Tweets
Y curioseando con R y apriori, nada nuevo se vé porque hay mucha data que opaca los casos inusuales. ¿Sería cuestión de eliminar el resto de la data y tomar sólo la minoritaria? como diferenciar casos raros.
lhs rhs support confidence lift
{Hundreds, Installing} => {Latin} 0.009911894 1.00000000 69.846154 {¡No,
al, aquí:,
asistir,
importa,,
online,
puedes} => {míralo} 0.006057269 1.00000000 165.090909
{ciudadades,
dmuchas,
es,
Festival,
Instalación,
Latinoamericano,
Software} => {Libre} 0.006607930 1.0000000 25.22222
{ciudadades,
contintente.,
dmuchas,
Festival,
Ho@wikinoticias:,
Instalación,
Latinoamericano,
Software} => {Libre} 0.005506608 1.0000000 25.22222
En resumen: muchos tweets sobre que es el FLISOL, en inglés y en español, y además si
no podías asistir compartían el enlace para visualizarlo por streaming, el usuario
wikinoticias también cubrió la noticia. Eliminando algunas palabras que son las mayoritarias:
lhs rhs support confidence lift
{#PanamGracias,
@Tecnomenia,
@utpfisc?,
míralo,
puedes} => {http://t.co/9yvPOaC7zI!} 0.004955947 1.0000000 201.77778
{#CiudadDeMéxico} => {#Hackerspace} 0.004405286 1.0000000 139.69231
Cuando aparecen las palabras del lado derecho seguido luego aparece un enlace para visualizarlo. Y la mención a esos usuarios de twitter. Estos usuario son de panamá: @utpfisc?, @Tecnomenia, @la_cascara y se meciona al flisol bogotá difundiendo sus sedes y varias ciudades de brasil que realizaron el flisol.